
The fastest way to create
trusted data
trusted data
Create high-quality data for machine learning, application development and testing with easy-to-use config files.
Write data requirements in a YAML config file for a database or using Python DSL for a dataset.
Create a data transformation job, check data categorization and access rights.
Run job as part of CI/CD or data pipeline to create data in the destination that meets the requirements.
Specify requirements
Create workflow
Run job
01
02
03
Create data with Augmedatum to:
Adopt DevOps for your database management
Make your database provisioning cloud-native using our database generation, masking and subsetting engine that runs in Kubernetes.
Why augmedatum
Automate test data management with the power of AI
No more manual configuration of complex data transformations. Use modern AI-driven techniques for data masking and generation.
Facilitate cloud migration
Synthetic high-quality database generation for functional validation, performance, and integration testing in the cloud for Snowflake, GCP, Amazon Redshift, and Microsoft Azure.
Shorten time to data
TDK
Create reusable data transformation workflows to shorten data collection lead time. Iteratively set up and test ML pipelines with Airflow, GCP Cloud Composer, Dbt, Spark, and other ETL tools instead of waiting for the lengthy original data access procedures.
Increase market value of existing data
Generation of high-quality synthetic data for data monetization with third-party firms that preserves statistical properties of original data and is free of sensitive PII/SPI data.
TDK
TDK
SDK
SDK
Automatic data rebalancing, upsampling, bootstrapping for backtesting, and data imputation to increase the performance of machine learning models by up to 15% without changing model structure.
SDK
Improve ML model performance
An API-first approach to create high-quality data
Faster outcomes
Fast & easy deployments
Simple API to integrate into your CI/CD or data pipeline, both on-premise and cloud. Supports all relational databases and data governance platforms (BigID, Collibra, Zaloni) and deployments using Kubernetes, OpenShift, and Docker.

Improved data quality
Our machine learning models learn statistical properties in a table and across tables to help create high-quality data, often better than production data.


Full automation
DevOps-friendly API-driven framework to create tabular data and databases in minutes using YAML config files and Python DSL.

Guaranteed compliance
"Data as Code" approach enables you to codify complex compliance requirements into concrete data transformations.
Create production-like data in your cloud tenant
Full integrations
Deploy instantly, supercharge effortlessly, and accelerate initiatives with seamless cloud marketplace integrations. “Data as Code” approach makes it easy for anyone to be a data engineer.
Whether you are a data engineer, data scientist, or machine learning researcher, Augmedatum SDK can be easily integrated into your existing workflows for ETL, data preparation, and model training. It's all set and ready to use.
Cloud
Cloud Dataproc



AWS
Run our products on AWS.

GCP

Run our products on GCP.

Microsoft Azure
Run our products on Microsoft Azure.
Our products
Create a generative model
for any dataset
Apply Augmedatum Scientific Data Kit (SDK) to bootstrap data where the density of data is low, automatically rebalance data to improve model performance, and anonymise data for repurposing.
Benefit from up to 15% uplift in model performance with data rebalancing, data imputation, and high-quality synthetic data generation. SDK helps increase revenue across conversion, fraud, revenue recovery, and more.
Improved model performance
Extend and plug-in into any data platform or ETL pipeline including Airflow, Dataproc, Spark. Fast and easy deployments using Kubernetes, OpenShift, and Docker.
API-first extensible framework
"Data as Code" approach enables you to codify complex compliance requirements into concrete data transformations.
Guaranteed
compliance
compliance

SDK
Full visibility of key data metrics including data quality, data compliance, and model performance metrics in your reports.
Full analytics and reporting



100+
~4-15%
<10 mins
#1
Model performance
improvement via
automated data quality
improvement via
automated data quality
Automated data compliance framework
To bootstrap data or
rebalance the
underlying dataset
rebalance the
underlying dataset
Supported ML models
and use cases
and use cases
Quality automation
Rebalancing
Compliance automation
Automate high-quality data creation using machine learning and common workflows.
Amplify the signal and reduce noise from original data. Multiple scenarios that allow for thorough model testing.
Automatic data upsampling and bootstrapping for backtesting, cross-validation and more. Unlimited volumes of data.
Codifying data compliance requirements into concrete data transformations.
Generate required volumes of anonymous data from generative models.
Robustness against complex attacks, such as linkage attacks and attribute disclosure.
Configure data masking parameters
to meet your organization’s needs.
Data compliance requirements verification
and validation.
Data
It’s all about
Bootstrapping

Our products
TDK
Create high-quality data for application teams
Use Augmedatum Test Data Kit (TDK) to create right-sized test databases you need — in minutes.
Reusable YAML configurations to create realistic production-like databases easily integrated into CI/CD pipelines.
CI/CD database automation
Automatically meet data quality requirements with data generation, subsetting, and masking for complex databases while preserving referential integrity and database logic.
Right-sized database creation
"Data as Code" approach enables you to codify complex compliance requirements into concrete data transformations.
Guaranteed
compliance
compliance
Augmedatum helps to measure test data coverage of your test cases via static SQL analysis and enables to generate optimised test data with 100% coverage.
Optimised test data coverage
TDK



Quality automation
10+
<1 min
<10 mins
#1
To install the TDK package in a local environment
Designed to support any relational database incl. PostgreSQL, Oracle, MySQL and MSSQL
For data masking and subsetting of 1GB of data
Automated data compilance framework
Subsetting
Generation
Automate high-quality data creation using machine learning and common workflows.
Database generation preserving distributions in a table and cross tables. Preserve primary and foreign key relationships and configure non-explicit relationships. Preserve logical relationships across tables including constraints, procedures, views, sequences and more.
Configure parameters on a database level such as the size ratio of the synthesized database. Mimic business rules and logic for specific generated tables or columns. Synthesize data for only selected columns in a table and use existing data for other columns.
Purpose-built for CI/CD - no custom UI or webhooks
Integrate config files for data transformations as easy as writing YAML
Data
It’s all about
CI/CD database automation


Reusable workflows
Compliance automation
Codifying data compliance requirements into concrete data transformations.
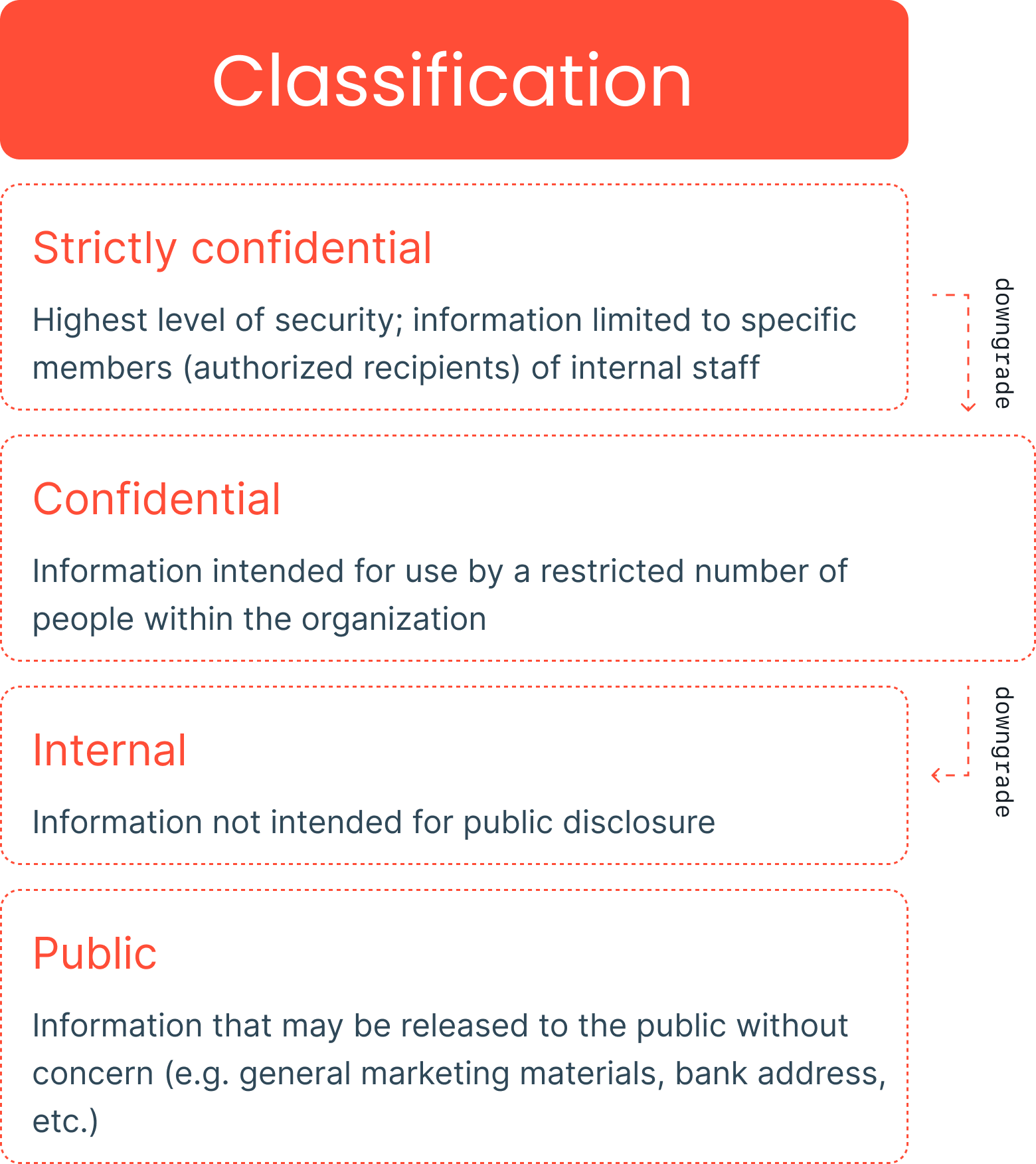
Data compliance requirements & verification
Data masking
Data anonymization
Synthetic data generation
Augmedatum delivers the fastest way to create and share trusted data
The inception of Augmedatum originates from a shared vision of Dmitry Bragin and Alexey Khromov, both hailing from diverse backgrounds in technology and real estate. Their combined expertise set the foundation for our venture. Our goal is to bring an innovative approach to the generation and processing of synthetic data, which would led to groundbreaking changes in machine learning and data science.
Augmedatum's journey began at a technology workshop in 2022, where Dmitry and Alexey, along with Alesia Dubrouskaya and Mikita Damashevich discovered a mutual passion for solving the modern problems of data usage in the field of artificial intelligence. This meeting quickly transitioned into action, with the founding of Augmedatum in March 2023. Identifying the critical gap in the availability of relevant and privacy-compliant data for AI development, the team embarked on developing a suite of tools that stand at the core of Augmedatum’s offerings: the AugDataGen SDK and the AugDataTest TDK.
Augmedatum's journey began at a technology workshop in 2022, where Dmitry and Alexey, along with Alesia Dubrouskaya and Mikita Damashevich discovered a mutual passion for solving the modern problems of data usage in the field of artificial intelligence. This meeting quickly transitioned into action, with the founding of Augmedatum in March 2023. Identifying the critical gap in the availability of relevant and privacy-compliant data for AI development, the team embarked on developing a suite of tools that stand at the core of Augmedatum’s offerings: the AugDataGen SDK and the AugDataTest TDK.
The company's development phases reflect a meticulous approach to innovation, from conducting in-depth market research to prototyping a platform capable of generating quality synthetic data.
Looking ahead, Augmedatum is poised to broaden its technological horizons, driving forward the fields of AI and ML with innovative, secure, and compliant synthetic data solutions. Our strategy involves a continuous loop of refinement and expansion, underscored by a significant investments in R&D. Our key technologies are ready and products are being tested, already bringing positive results to our customers. Learn more about our our offerings and exclusive capabilities by contacting our sales department!
Looking ahead, Augmedatum is poised to broaden its technological horizons, driving forward the fields of AI and ML with innovative, secure, and compliant synthetic data solutions. Our strategy involves a continuous loop of refinement and expansion, underscored by a significant investments in R&D. Our key technologies are ready and products are being tested, already bringing positive results to our customers. Learn more about our our offerings and exclusive capabilities by contacting our sales department!
Our story
About us
Founders
Khromov
Alexey
Alexey
Chief Technology Officer
Bragin
Dmitry
Dmitry
Chief Executive Officer
Dubrouskaya
Alesia
Alesia
Chief Marketing Officer
Damashevich
Nikita
Nikita
Chief Product Officer
Svetlana Korneva
Chief Financial Officer
Thank you!
Please send your CV to e-mail job@augmedatum.com with the position name in the title
Don't see the role you're interested in?
We’re always looking for talented people to join our team. Send us your CV and we will contact you for any future roles.
Pricing that fits your needs
Unlimited number of developers
Developer
Free
Add products to your development stack
• SDK Developer
• TDK Developer
• Fairlens
Unlimited number of developers
Enterprise
For Data Innovation
• Anonymized Data Generation
• Flexible Data Structuring
• Seamless ML Integration
• Advanced Data Simulation
Featured highlights
SDK
• Regulatory Compliance
TDK
Enterprise
For more security and control
Featured highlights
• Data Suitability Analysis
• Anonymity Checks
• Performance Evaluation
• Accuracy Verification
• Automated Testing Tools
On-premise/Cloud
On-premise/Cloud
Contact Sales
• Easy onboarding
• Ongoing support
• Hassle free
Start a conversation with us today about how Augmedatum can help you solve your data challenges.
After you submit your request, we’ll get in touch with you shortly to suggest a time for an introductory call.
Our promise
Send request